

Anthropic officially unveiled Claude Opus 4.6 on February 5, 2026, its most advanced AI model to date — and one that marks a genuine turning point in professional AI assistance.
With a 1-million-token context window and record-breaking results in programming and long-horizon tasks, Opus 4.6 now outperforms OpenAI’s GPT-5.2 on several industry benchmarks.
Beyond raw performance, the real shift is qualitative: Claude Opus 4.6 is no longer just a powerful assistant. It behaves increasingly like a persistent, autonomous collaborator capable of reasoning, reviewing its own work, and operating across massive codebases without losing focus.
Record-breaking performance in agentic coding benchmarks
Claude Opus 4.6 sets a new bar for AI-driven programming. The model demonstrates stronger planning abilities, improved long-term concentration, and a much higher capacity to navigate large and complex codebases.
One notable advance is its ability to detect and correct its own mistakes during code review — a long-standing weakness in previous generations.
Those improvements translate directly into benchmark dominance. On Terminal-Bench 2.0, the leading evaluation for agentic coding systems, Opus 4.6 achieves 65.4%, the highest score ever recorded.
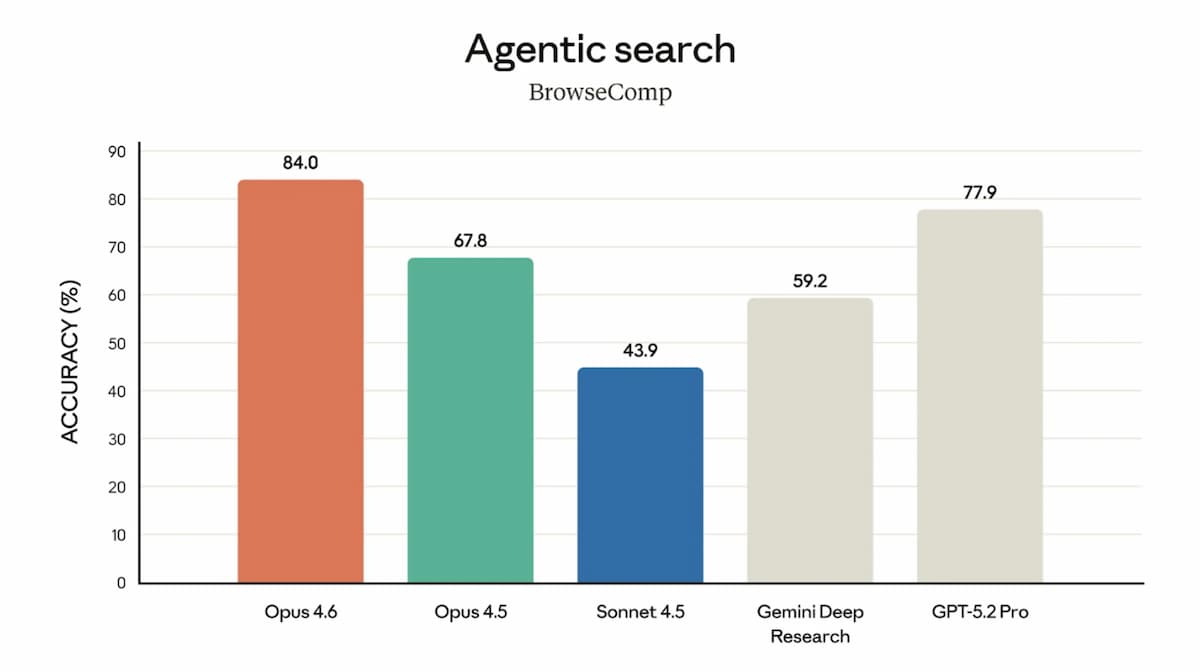
On GDPval-AA, which measures real-world professional tasks in finance and legal workflows, it reaches 1606 Elo — a 144-point lead over GPT-5.2. The model also tops BrowseComp, which evaluates the ability to locate hard-to-find information across the web.
Michael Truell, co-founder of AI coding platform Cursor, notes that “Claude Opus 4.6 excels on the hardest problems. It shows greater persistence, stronger code review, and the ability to stay on long tasks where other models tend to give up.”
GitHub’s Mario Rodriguez echoes the sentiment, saying the model is now unlocking long-horizon tasks that were previously achievable only by humans.
A million-token context window changes document-scale reasoning
Claude Opus 4.6 is the first model in the Opus line to support a 1-million-token context window, dramatically expanding its ability to process and reason over massive document collections.
In practical terms, it can now ingest the equivalent of multiple books at once without performance collapse.
This improvement is reflected in the MRCR v2 benchmark, where Opus 4.6 scores 76%, compared to just 18.5% for Sonnet 4.5.
The notorious “context rot” problem — where long conversations degrade model performance — is effectively eliminated.
With Claude Code, developers can now create teams of AI agents that collaborate in parallel on complex projects. Instead of a single assistant handling tasks sequentially, multiple agents can work simultaneously on different components.
Sarah Sachs, Head of AI at Notion, describes the model as no longer feeling like a tool, but “a truly capable collaborator.”
Deep integration into everyday office tools
Anthropic is also pushing Claude deeper into daily professional workflows, with a strong emphasis on Microsoft Office integrations. Claude in Excel can now interpret messy spreadsheets without explicit explanations, while Claude in PowerPoint — currently in preview — generates presentations that automatically match existing colors, fonts, and layouts.
These features are reserved for Max, Team, and Enterprise plans, but they highlight a broader strategy: embedding AI directly into familiar office environments rather than isolating it as a standalone chatbot.
Pricing remains unchanged despite major capability gains
Despite the significant leap in performance, Anthropic has kept pricing unchanged. Processing one million tokens costs $5, while generating one million tokens costs $25 — an aggressive stance aimed at maintaining pressure on competitors.
Claude Opus 4.6 is available immediately via API across major cloud platforms including Amazon and Google Cloud.
The API introduces several notable upgrades. Adaptive Thinking dynamically adjusts reasoning depth based on task complexity, with four selectable intensity levels. Context Compaction automatically summarizes older conversation segments when memory fills up, enabling extremely long interactions without crashes or forgetting.
Safety remains a core focus
Anthropic insists that safety has not been sacrificed for performance. According to the company, Opus 4.6 demonstrates the strongest safety profile in the industry, with extremely low rates of harmful or unintended behaviors.
The model underwent the most extensive evaluation pipeline Anthropic has ever deployed, including new user well-being assessments and six novel cybersecurity stress tests. As AI systems become more autonomous, this level of scrutiny is increasingly critical.
That said, competition is far from over. OpenAI has already responded with the launch of GPT-5.3-Codex, its most advanced agentic coding model yet — ensuring that the AI arms race remains very much alive.